|
|
|
@@ -0,0 +1,27 @@ |
|
|
|
Databases are so integrated into the computational systems behind contemporary life that their functions are often hidden from us. Every time you log in to a website, your login details are pulled from a database. Every time you look at a tweet or an Instagram post, the content is pulled from a database. Every time you access a file in a document management platform like Nextcloud or Microsoft SharePoint, the link to the file is retrieved from a database. Relational databases are the silent background to our modern computer interactions. |
|
|
|
|
|
|
|
A database is an organised collection of data. In computer systems, data is often stored in a relational database based on the relational model of data proposed by IBM computer scientist E. F. Codd (1970, p. 377) in his 1970 article in *Communications of the ACM*. Codd proposed "12 Principles of Relational Databases" (Kline, Gould and Zanevsky, 1999, p. 5) which specify how data can be organised in rows and columns in tables and then linked to other pieces of data through their relationships (although since lists in computer systems often treat 0 as the start of an ordered list, there are actually thirteen rules). This relational model forms the basis of the modern relational database management systems that power websites and web applications: open source MySQL used by Facebook, Twitter, and YouTube; open source MariaDB used by Mozilla, Google, and Wikipedia; open source PostgreSQL used by OpenStreetMap, Reddit, Instagram, and the International Space Station; and closed source systems like Oracle or Microsoft SQL. |
|
|
|
|
|
|
|
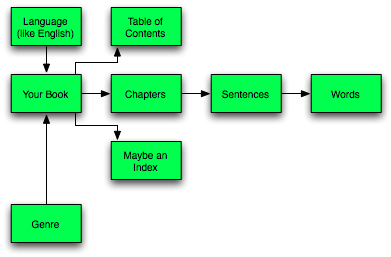
But if we go back and consider databases using their most basic definition as an 'organised collection of data', then a book can also be considered a database of sorts. Chris Kubica (2010) considers the analogy of books as relational databases and imagines the data relationships between parts of a book like chapters, table of contents, and index drilling down on the chapters to discover the sentences within and the words nested within the sentences. |
|
|
|
|
|
|
|
The Performing Patents Otherwise publication provides an interesting way to conceive of database as book by offering one way of turning a dataset into a publication. We've turned the curated and enhanced Politics of Patents dataset into a hybrid digital publication combining a robust search engine with textual 'book-type' content to facilitate conversations and creative interventions with the data itself. In many ways, we've deliberately subverted the traditional principles behind relational databases and search engines in order to facilitate creativity and serendipity through computational randomness. |
|
|
|
|
|
|
|
As Open Source Software Developer for the COPIM project, I was brought in to help consider how the dataset of patents curated by the Politics of Patents research project could be turned into a publication as part of COPIM's work package supporting experimental open access publishing. The dataset consists of approximately 320,000 patents for clothing and wearable technology from the European Patent Office comprising RTF files and accompanying PDF files arranged in a directory structure by year of patent registration followed by country code of originating country. Each RTF file contains basic bibliographic details including patent title, application ID, publication ID, a short description or abstract describing the patent, and International Patent Classification (IPC) number. Each ID is itself structured data containing an ISO 3166 alpha-2 country code (e.g. GB for the United Kingdom) and an ISO 8601 date of application or publication. |
|
|
|
|
|
|
|
It's a wonderful dataset to browse through discovering fascinating and unexpected clothing designs and wearable inventions and we wanted to preserve that sense of randomly opening a file to discover something wonderfully weird while also making the data accessible in a modern way alongside published chapters. |
|
|
|
|
|
|
|
To make the dataset accessible and searchable, I wanted to put the data into a search engine. In my previous work on library catalogue and search systems I'd worked with Apache Solr, a reliable open source search engine offering full-text search, faceted search, and advanced customisation. Solr is able to index RTF files using Apache Tika's framework for extracting metadata and text from a range of document formats. We've made some customisations to Solr's config to extract and index 'year' and 'country' data for each document using regular expressions to find the data in the document text. |
|
|
|
|
|
|
|
The Solr search engine allows us to run search queries against the full text but it doesn't offer a built-in frontend for doing so. Using Flask, a web framework written in Python, I built a website frontend with a searchbox that queries the Solr search engine and presents the results in an accessible way parsing out title, abstract, year of publication, country of origin, and document ID. Additionally by using the document ID to query the the European Patent Office's Open Patent Services API, I was able to enhance the data we presented for each record by automatically pulling data like original language title, original language abstract, and images of the original patents. The images such as drawings from the patents often provide a new perspective on the inventions and clarify what is described in the abstracts. |
|
|
|
|
|
|
|
Solr provides a reliable and robust search engine but we wanted to experiment with the idea of a search engine to reconceptualise how the data in this database book could be represented. The traditional function of a search engine is to help lead a user towards a specific document that matches their search query. This is the case with library catalogues and archive search engines. As Marshall Breeding (2015) writes: |
|
|
|
|
|
|
|
> One dimension of this experience relates to satisfying those with something specific in mind. These patrons may have a favorite author or topic in mind and want specific resources, which might include the next book by that author or an exhaustive set of materials in the bibliography of a research topic. The catalogs and discovery services that libraries present to their users are designed especially for these kinds of information fulfillment activities. |
|
|
|
|
|
|
|
But what if a user doesn't have a specific document in mind? This is a question I came across as a library systems developer in relation to browsing and serendipity. Part of the joy of going to a physical library is browsing the shelves and serendipitously discovering texts that they might otherwise have never come across: "How many times do we visit a library or bookstore expecting that something interesting will catch our attention?" (Breeding, 2015) Replicating this browsing experience in automated library catalogues and search engines has posed a challenge for library system developers. |
|
|
|
|
|
|
|
To infuse the search engine for the patents data with serendipity, we inserted a large degree of randomness into the design of the system. You can inject randomness into a computer system by inserting a random number into an algorithm like a search engine request but unfortunately computers are not good at creating randomness. A computer system is designed to follow instructions to the letter. Erin Herzstein (2021) sums this up by asking "How does a computer, a machine defined by its adherence to instructions and formulae, generate a random outcome?" Computers can create randomness in two major ways. First, true random number generators produce random numbers by "harvesting entropy" (Herzstein, 2021): they take unpredictable input from some external source such as a user randomly moving their finger around a laptop trackpad or mashing buttons on a keyboard or atmospheric noise like static. Second, pseudo-random number generators use algorithms to generate numbers that appear to be random to a human but aren't truly mathematically random. Pseudo-random number generators perform mathematical formulae a number of times to produce an outcome that appears random but is actually determined by the formulae. |
|
|
|
|
|
|
|
We use a pseudo-random number generator in the form of Python randint() method (https://docs.python.org/3/library/random.html). The line `rand = str(random.randint(0, 9999999))` produces a random integer in the range 0 to 9,999,999. We then make a request to the Solr search engine inserting that random number as part of a parameter for sorting the results: `solrurl = 'http://' + solr_hostname + ':' + solr_port + '/solr/' + core + '/select?q.op=OR&q=*%3A*&wt=json&sort=random_' + rand + '%20asc&rows=1'`. In essence, this sorts the search results differently every time and we pick the top result like picking the top card from a freshly shuffled deck of cards. |
|
|
|
|
|
|
|
Building on this basic bit of code, we were able to build a number of interesting functions to randomly explore the dataset and serendipitously discover interesting patents. |


{kind=link}